
😎 공부하는 징징알파카는 처음이지?
[DEEPNOID 원포인트레슨]_9_AutoEncoder & GAN 본문
220128 작성
<본 블로그는 DEEPNOID 원포인트레슨을 참고해서 공부하며 작성하였습니다>
인공지능 | Deepnoid
DEEPNOID는 인공지능을 통한 인류의 건강과 삶의 질 향상을 기업이념으로 하고 있습니다. 딥노이드가 꿈꾸는 세상은, 의료 인공지능이 지금보다 훨씬 넓은 범위의 질환의 연구, 진단, 치료에 도움
www.deepnoid.com
1. AutoEncoder
: 차원이 축소된 입력데이터를 얻기 위해 비슷한 데이터로 표현하는 것을 배움
: 입력, 출력 같은 구조
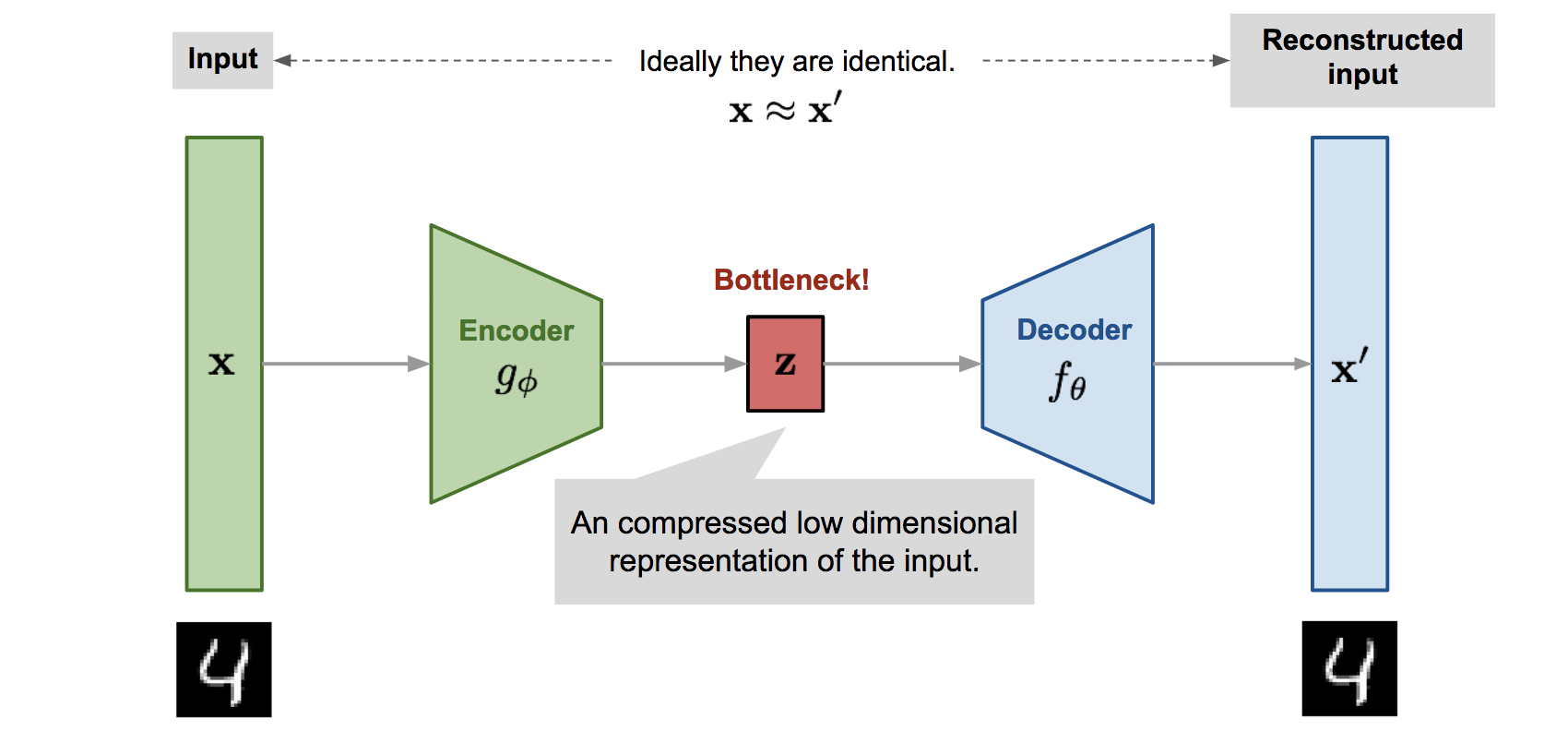
- Encoder
: 입력값을 받아 특징 값으로 변환하는 신경망
- Decoder
: 특징값을 출력값을 변환하는 신경망
- Latent Feature
신경망 내부에서 추출된 특징적 값들
1) Unsupervised learning - 학습방법
2) MY density estimation - loss 는 neagtive ML 로 해석
3) Manifold learning - 인코더는 차원 축소 역할 수행
: 원본의 traing DB 데이터를 잘 표현하는 원본 공간에서의 subspace
: 잘 찾은 manifold 에서 projection 시키면 데이터 차원이 추소 될 수 있음
- 차원의 저주
-> 데이터 타원이 증가할수록 해당 공간의 크기가 기하급수적으로 증가
-> 동일한 개수의 데이터 밀도는 급속도로 희박
-> 차원이 증가하면, 데이터 분포 분석 or 모델 추정에 필요한 샘플 데이터 개수 증가
- discover most important feautre
: 학습 결과를 평가하기 위해 manifod 좌표들이 조금씩 변할 대 데이터도 유의미하게 조금 변함이 보인다
- reasenable distance metrics
: 고차원 공간에서 가까운 두 샘플들은 의미적으로 굉장히 다름
: 의미적으로 가깝다고 생각되는 고차원 공간의 두 샘플 간들 간의 거리는 먼 경우가 많다
2. AE 학습 과정
: Input x 를 Encoder Network 에 통과시켜 압축된 Latent Vector z 를 얻음
: Loss 는 output이 input 과 얼마나 유사한지 비교
: 입출력이 동일한 네트워크
: output 을 input으로 복원
=> input, output 같도록 학습하기 때문에, Decoder 은 최소한 학습에 사용한 데이터는 잘 생성 -> but 생성 데이터는 학습과 비슷
=> Encoder 은 최소한 학습 데이터는 latent vector 로 잘 표현 -> 데이터 추상화에 많이 쓰임
3. Generative model
: 기존 데이터 분포에서 sampling 한 것 같은 새로운 데이터 만들기
: want to learn p(model) similar to p(data)
1) Variational AutoEncoder (VAE)
: Variational inference 를 오토 인코더의 구조를 통해 구현한 생성신경망
: autoencoder 과 vae 는 전혀 관계 없음
: encoder 단을 학습하기 위해 encoder 붙임
: Generative model
( Autoencoder 은 encoder 단을 학습하기 위해 decoder 단 붙임, manifold learning 목적)
2) Generative Adversarial Network (GAN)
: 새로운 데이터를 생성하기 위해 뉴럴 네트워크로 이루어진 생성자 (generative) 와 판별자 (discriminator) 가 서로 겨루며 훈련
: 실제 데이터의 분포와 모델이 생성한 데이터의 분포 간의 차이 줄이기
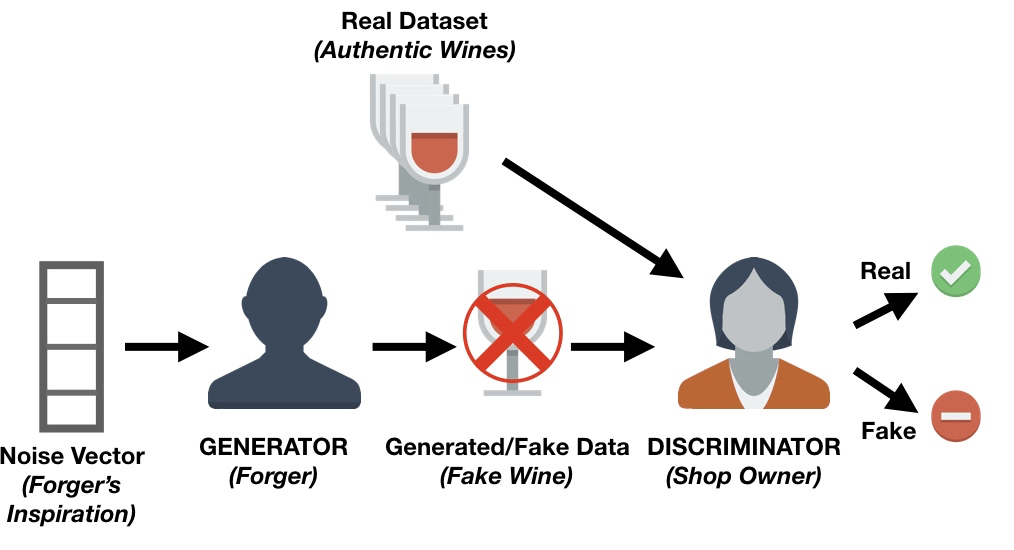
- Generator
: 랜덤 노이즈 벡터 입력 받아 이미지를 만드는 업 샘플링 진행
: 실제 이미지 x 의 분포를 알아내기 위해 노력
: 가짜 이미지 샘플 G(x)의 분포를 정의하는 모델
=> training dataset 에 있는 sample x 와 구별이 불가능한 fake sample G(x) 생성
진짜 화폐랑 내가 만든 화폐를 구분할 수 없도록 완벽한 가짜 화폐 만들자!
- Discrimitor
진짜 화폐랑 G 가 만든 가짜 화폐를 구별하자!
: 진짜는 진짜 1, 가짜는 가짜 0 으로 구분하도록 학습
: 샘플이 x 인지 혹은 가짜이미지 G(x) 인지 구별하여 샘플이 진짜일 확률 계산
=> Generator 가 만든 fake sample G(x) 과 training dataset 의 real sample x 구별
: GAN 식

=> minimax problem of GAN has a global optimum at p(g) = p(data)
=> proposed algorithm can find that global optimum
3) Deep Convolutional GAN (DCGAN)
: Z space 에서 벡터 산술 연산 가능
: 대부분 상황에서 언제나 안정적으로 학습이 되는 구조 제안
: DCGAN 으로 학습된 G가 벡터 산술 연산이 가능한 성질을 갖고, 의미론적으로 신규 샘플 생성
'👩💻 인공지능 (ML & DL) > ML & DL' 카테고리의 다른 글
| [CNN]_Convolution 과정 (0) | 2022.01.29 |
|---|---|
| [DEEPNOID 원포인트레슨]_10_GAN (0) | 2022.01.28 |
| [Deep Learning]_1_머신러닝 수학 (0) | 2022.01.28 |
| [DEEPNOID 원포인트레슨]_8_Reinforcement Learning (0) | 2022.01.27 |
| [DEEPNOID 원포인트레슨]_7_Object Detection 2 (0) | 2022.01.27 |

