
😎 공부하는 징징알파카는 처음이지?
[Kaggle]Pneumonia/Normal Classification(CNN) 본문
728x90
반응형
220320 작성
<본 블로그는 Kaggle 을 참고해서 저만의 풀이를 작성하였습니다>
https://www.kaggle.com/code/rafetcan/pneumonia-normal-cnn-model/notebook
🩺 Pneumonia/Normal ? - CNN Model 🩺
Explore and run machine learning code with Kaggle Notebooks | Using data from Chest X-Ray Images (Pneumonia)
www.kaggle.com
1. Data
- 3 folders (train, test, val)
- each image category (Pneumonia/Normal)
- 5,863 X-Ray images (JPEG) and 2 categories (Pneumonia/Normal)
2. import libraries
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
import matplotlib.pyplot as plt
import os
from glob import glob
import cv2
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
from tensorflow.keras.callbacks import EarlyStopping
# import warnings
import warnings
# filter warnings
warnings.filterwarnings('ignore')
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
3. file 경로 지정
train_dir = '/content/drive/MyDrive/2022/project/Data/chest_xray/train'
test_dir = '/content/drive/MyDrive/2022/project/Data/chest_xray/test'
val_dir = '/content/drive/MyDrive/2022/project/Data/chest_xray/val'
4. read image & train_test split
def picture_separation(folder):
y = []
x = []
image_list = []
for foldername in os.listdir(folder):
if not foldername.startswith('.'):
if foldername == "NORMAL":
label = 0
elif foldername == "PNEUMONIA":
label = 1
else:
label = 2
for image_filename in os.listdir(folder + "/"+ foldername):
img_file = cv2.imread(folder + "/" + foldername + '/' + image_filename,0)
if img_file is not None:
img = cv2.resize(img_file,(64,64))
img_arr = img_to_array(img) / 255
x.append(img_arr)
y.append(label)
image_list.append(foldername + '/' + image_filename)
X = np.asarray(x)
y = np.asarray(y)
return X,y,image_list
- train_df
X_train, y_train, img_train = picture_separation(train_dir)
train_df = pd.DataFrame(img_train, columns=["images"])
train_df["target"] = y_train
train_df.info()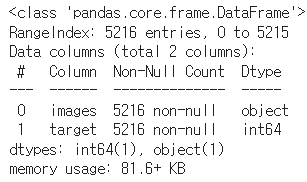
sns.countplot(train_df["target"])
plt.title("NORMAL/PNOMONİA")
plt.show()
print(train_df["target"].value_counts())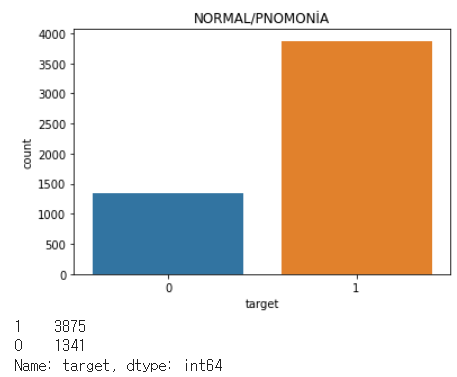
- val_df
X_val, y_val, img_val = picture_separation(val_dir)
val_df = pd.DataFrame(img_val, columns=["images"])
val_df["target"] = y_val
sns.countplot(val_df["target"])
plt.title("NORMAL/PNOMONİA")
plt.show()
print(val_df["target"].value_counts())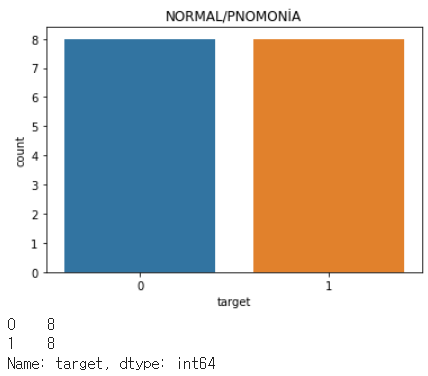
- test_df
X_test, y_test, img_test = picture_separation(test_dir)
test_df = pd.DataFrame(img_test, columns=["images"])
test_df["target"] = y_test
sns.countplot(test_df["target"])
plt.title("NORMAL/PNOMONİA")
plt.show()
print(test_df["target"].value_counts())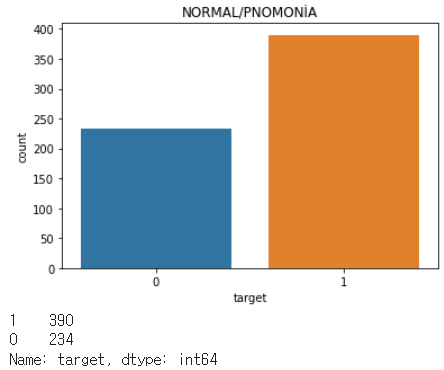
- full_data
full_data = pd.concat([train_df, test_df, val_df], axis=0, ignore_index=True)
print(full_data.head())
print(full_data.tail())
- 시각화
plt.figure(figsize=(12,8))
img = load_img(train_dir + "/" + full_data["images"][3875])
plt.imshow(img)
plt.title("NORMAL", color = "green", size = 14)
plt.grid(color='#CCCCCC', linestyle='--')
plt.show()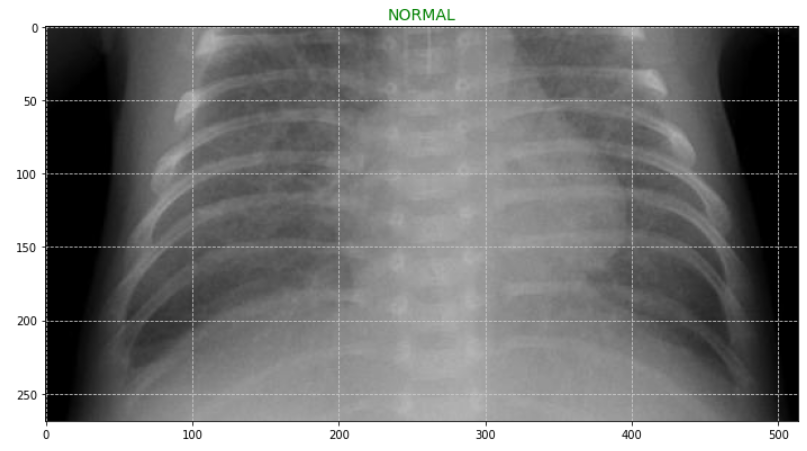
plt.figure(figsize=(10,7))
img = load_img(train_dir + "/" + full_data["images"][0])
plt.imshow(img)
plt.title("PNEUMONIA", color = "green", size = 14)
plt.grid(color='#CCCCCC', linestyle='--')
plt.show()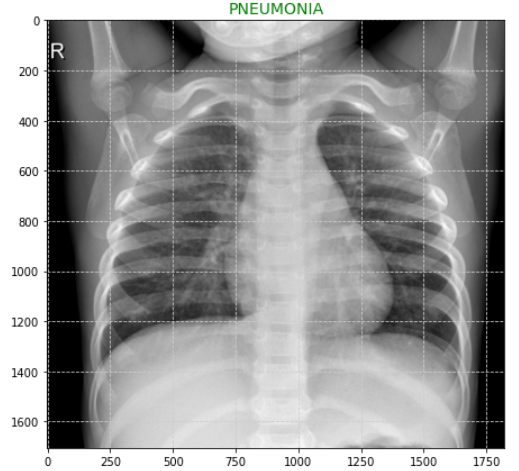
sns.countplot(full_data["target"])
plt.title("NORMAL/PNOMONİA")
plt.show()
print(full_data["target"].value_counts())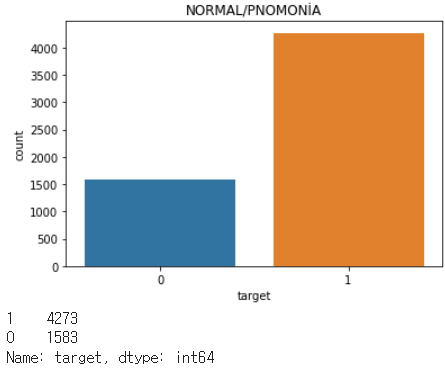
5. 시각화
plt.figure(figsize=(15,8))
plt.subplot(2,3,1)
img = load_img(train_dir + "/" + full_data["images"][0])
plt.imshow(img)
plt.title("PNEUMONIA", color = "blue", size = 14)
plt.axis("off")
plt.subplot(2,3,2)
img = load_img(train_dir + "/" + full_data["images"][1])
plt.imshow(img)
plt.title("PNEUMONIA", color = "blue", size = 14)
plt.axis("off")
plt.subplot(2,3,3)
img = load_img(train_dir + "/" + full_data["images"][10])
plt.imshow(img)
plt.title("PNEUMONIA", color = "blue", size = 14)
plt.axis("off")
plt.subplot(2,3,4)
img = load_img(train_dir + "/" + full_data["images"][3875])
plt.imshow(img)
plt.title("NORMAL", color = "green", size = 14)
plt.axis("off")
plt.subplot(2,3,5)
img = load_img(train_dir + "/" + full_data["images"][3876])
plt.imshow(img)
plt.title("NORMAL", color = "green", size = 14)
plt.axis("off")
plt.subplot(2,3,6)
img = load_img(train_dir + "/" + full_data["images"][3877])
plt.imshow(img)
plt.title("NORMAL", color = "green", size = 14)
plt.axis("off")
plt.suptitle("NORMAL or PNEUMONIA", size = 16, color = "darkred")
plt.show()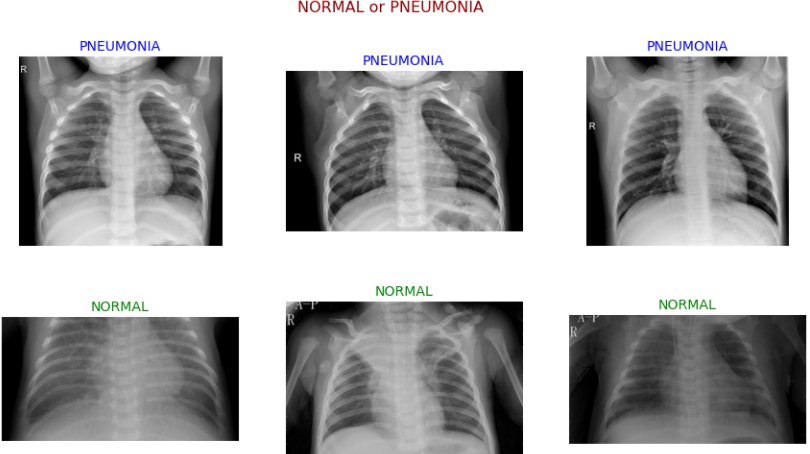
X_train.shape
className = glob(train_dir + '/*' )
numberOfClass = len(className)
print("NumberOfClass: ",numberOfClass)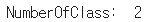
6. 데이터 증강
batch_size = 32
train_datagen = ImageDataGenerator(rescale= 1./255,
shear_range = 0.3,
horizontal_flip=True,
zoom_range = 0.3)
test_datagen = ImageDataGenerator(rescale= 1./255)val_datagen = ImageDataGenerator(rescale= 1./255)
- train
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(64, 64),
batch_size = batch_size,
color_mode = "grayscale",
class_mode= "binary")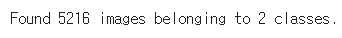
- test
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(64, 64),
batch_size = batch_size,
color_mode = "grayscale",
class_mode= "binary")
- val
val_generator = test_datagen.flow_from_directory(
val_dir,
target_size=(64, 64),
batch_size = batch_size,
color_mode = "grayscale",
class_mode= "binary")
7. model 생성
X_train.shape[1:]
model = Sequential()
model.add(Conv2D(32,(3,3),input_shape = X_train.shape[1:]))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Conv2D(64,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(Dropout(0.4))
model.add(Dense(1)) # output
model.add(Activation("sigmoid"))
model.compile(loss = "binary_crossentropy",
optimizer = "rmsprop",
metrics = ["accuracy"])
- early stopping
: 과대적합 되기전에 early! stop 하기
early_stopping = EarlyStopping(monitor='val_loss', mode='min', verbose=1,patience=2)history = model.fit_generator(
train_generator,
steps_per_epoch=5216//32,
epochs=20,
validation_data=test_generator,
validation_steps=624//32,
callbacks=[early_stopping])
print("Accuracy of the model is - " , model.evaluate_generator(test_generator)[1]*100 , "%")
print("Loss of the model is - " , model.evaluate_generator(test_generator)[0])
8. 시각화
history.history.keys()
- loss
plt.figure()
plt.plot(history.history["loss"],label = "Train Loss")
plt.plot(history.history["val_loss"],label = "Validation Loss")
plt.legend()
plt.show()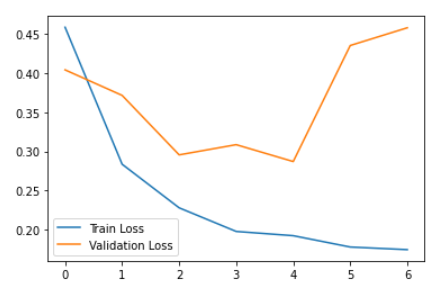
- accuracy
plt.figure()
plt.plot(history.history["accuracy"],label = "Train Accuracy")
plt.plot(history.history["val_accuracy"],label = "Validation Accuracy")
plt.legend()
plt.show()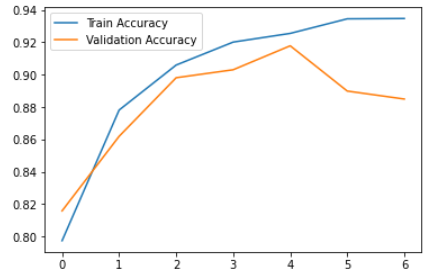
728x90
반응형
'👩💻 컴퓨터 구조 > Kaggle' 카테고리의 다른 글
| [Kaggle] Best Book to Read in 2021 탐색적 데이터 분석 (plotly 시각화) (0) | 2022.11.11 |
|---|---|
| [Kaggle] Credit Card Anomaly Detection (0) | 2022.11.02 |
| [Kaggle]Super Image Resolution_고화질 이미지 만들기 (0) | 2022.02.07 |
| [Kaggle] CNN Architectures (0) | 2022.02.04 |
| [Kaggle] HeartAttack 예측 (0) | 2022.01.31 |
'👩💻 컴퓨터 구조/Kaggle' Related Articles
more



