
😎 공부하는 징징알파카는 처음이지?
[Kaggle]MBTI_Myers-Briggs Personality Type Dataset(성격연구) 본문
220122 작성
<본 블로그는 Kaggle 을 참고해서 저만의 풀이를 작성하였습니다>
https://www.kaggle.com/laowingkin/mbti-study-personality
MBTI - Study personality
Explore and run machine learning code with Kaggle Notebooks | Using data from (MBTI) Myers-Briggs Personality Type Dataset
www.kaggle.com
안궁금하겠찌만,,, ㅎ
쓰니의 MBTI 는 ENFJ!!
징징알파카의 MBTI 는 INSF!!
1. MBTI 데이터
: MBTI 는 4가지 주요 심리적 기능인 감각, 직관, 느낌 및 사고를 사용하여 인간이 경험하는 일종의 심리학적 분류
- 내향성(I) – 외향성(E)
- 직관(N) – 감각(S)
- 생각(T) – 느낌(F)
- 판단(J) – 인식(P)
: 데이터 세트에는 8600개 이상의 데이터 행이 포함되어 있으며 각 행에는 다음이 포함
- 유형 (이 사람 4글자 MBTI 코드/유형)
- 최근에 게시한 50개 항목의 섹션(각 항목은 "|||"(파이프 문자 3개)로 구분됨)
: 기본 용도
- 기계 학습을 사용하여 MBTI의 유효성과 온라인에서 언어 스타일 및 행동을 예측하는 능력을 평가
- 그들이 작성한 일부 텍스트를 기반으로 사람의 성격 유형을 결정하려고 시도할 수 있는 기계 학습 알고리즘의 생산
2. 데이터 분석
- import
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt- read_csv
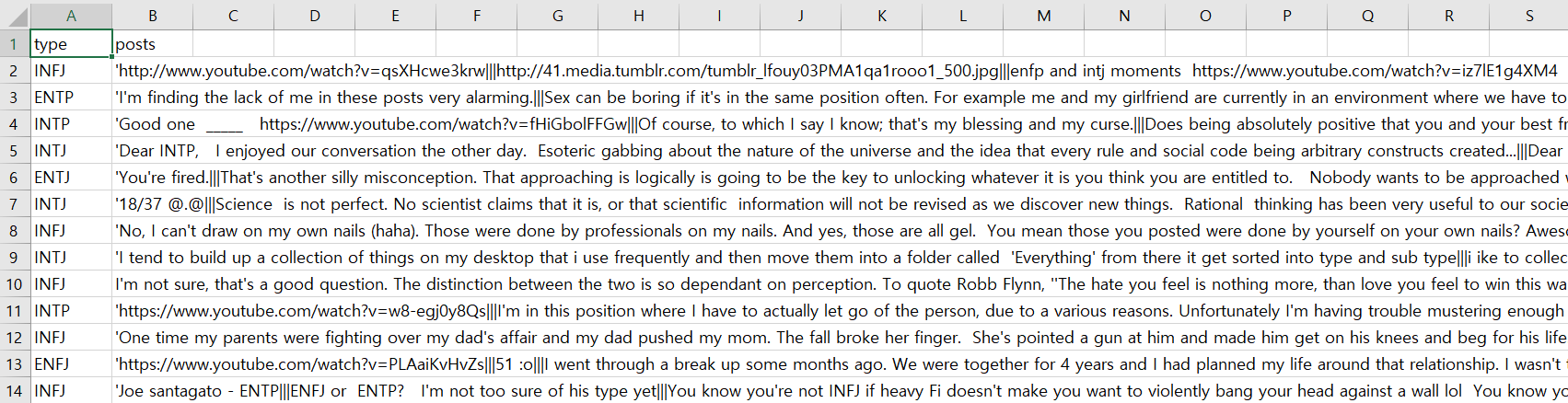
df = pd.read_csv("/content/drive/MyDrive/></2022/MBTI/mbti_1.csv")
df.head()- info()
df.info()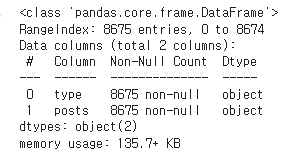
- value_counts()
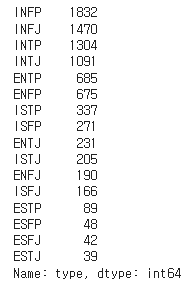
df['type'].value_counts()
- "|||" 으로 구분 되어 있는 걸 split!
- comment 마다의 words 와, words 의 개수를 분산으로 ㄱ ㄱ
def var_row(row) :
l = []
for i in row.split("|||") : # 50개 항목의 섹션(각 항목은 "|||"(파이프 문자 3개)로 구분됨)
l.append(len(i.split()))
return np.var(l)
# numpy.var(a, axis=None, dtype=None, out=None, ddof=0, keepdims=<no value>, *, where=<no value>)[source]
# 지정된 축을 따라 분산을 계산
# 열 생성
df['words_per_comment'] = df['posts'].apply(lambda x : len(x.split())/50) # 왜 50으로 나눌까 아 적은 포스트가 50개!
df['variance_of_word_counts'] = df['posts'].apply(lambda x : var_row(x)) # 분산!
df.head()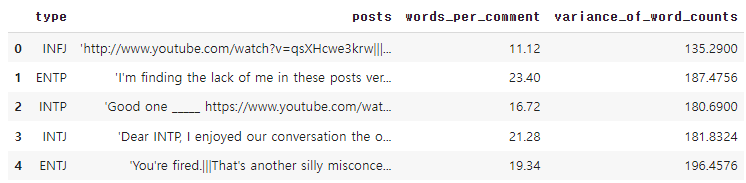
+) 분산은! 어케 구하냐!
numpy.var(a, axis=None, dtype=None, out=None, ddof=0, keepdims=<no value>, *, where=<no value>)[source]: 관측값에서 평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한다
: 즉, 차이값의 제곱의 평균
- sns 을 사용하여
plt.figure(figsize = (15,10))
sns.swarmplot("type", "words_per_comment", data = df)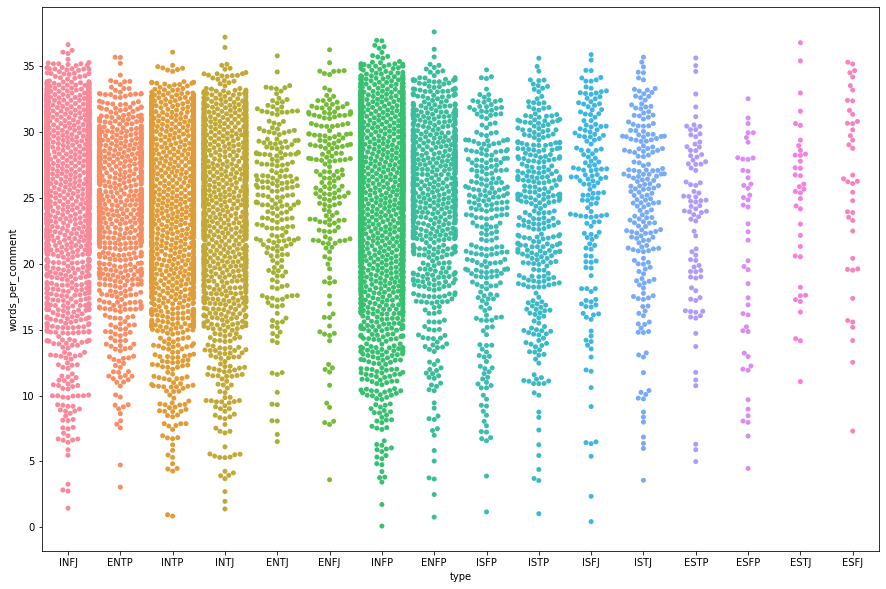
- groupby 와 agg 합해서 count 적용
# df에서 type 를 그룹(묶고)만들고, agg해서 type 의 count 구하기
df.groupby("type").agg({"type" : "count"})
- 이해가 안됨. 왜 저 네개를 빼는거지 ?
# 왜 저 네개의 MBTI 는 뺏을까??
# isin() 메소드 안의 값이 들어 있으면 True, 아니면 False 반환
df_2 = df[~df['type'].isin(['ESFJ', 'ESFP', 'ESTJ', 'ESTP'])]
df_2['http_per_comment'] = df_2['posts'].apply(lambda x : x.count("http")/50)
df_2['qm_per_comment'] = df_2['posts'].apply(lambda x : x.count("?")/50)
df_2.head(): 4개의 MBTI를 뺀 df_2 에서 http 나 ? 가 들어간 것의 개수를 50으로 나눔~
- 평균도 만들고
df_2.groupby("type").agg({"http_per_comment" : "mean"})df_2.groupby("type").agg({"qm_per_comment" : "mean"})
- MBTI 마다 이변량 및 일변량 그래프를 사용하여 두 변수의 플롯 을 그림
https://seaborn.pydata.org/generated/seaborn.jointplot.html 참고
def plot_jointplot(mbti_type, axs, titles) :
df_3 = df_2[df_2["type"] == mbti_type]
sns.jointplot("variance_of_word_counts", "words_per_comment", data = df_3, kind = "hex", ax = axs, title = titles)
i = df_2["type"].unique()
k = 0
for m in range(0, 2) :
for n in range(0, 6) :
df_3 = df_2[df_2['type'] == i[k]]
sns.jointplot("variance_of_word_counts", "words_per_comment", data = df_3, kind = "hex")
plt.title(i[k])
k += 1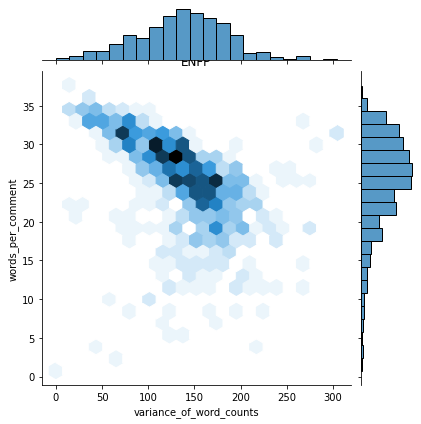
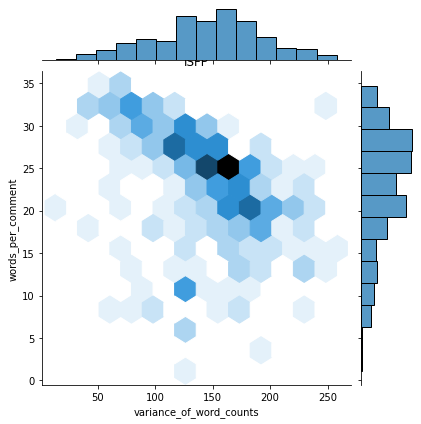
: 이런게 12개 펼쳐짐
: 한눈에 비교도 쉽움
- 핵심단어 시각화
from scipy.misc import imread
from wordcloud import WordCloud, STOPWORDS
# 워드 클라우드 (wordcloud) : 특정 데이터나 텍스트에 자주 등장하는 핵심단어 시각화
fig, ax = plt.subplots(len(df['type'].unique()), sharex = True, figsize = (155, 10*len(df["type"].unique())))
k = 0
for i in df['type'].unique() :
df_4 = df[df["type"] == i ]
wordcloud = WordCloud().generate(df_4['posts'].to_string())
ax[k].imshow(wordcloud)
ax[k].set_title(i)
ax[k].axis("off")
k += 1

.. 흠 징징이는 YOUTUBE 를 좋아하나봥
'👩💻 컴퓨터 구조 > Kaggle' 카테고리의 다른 글
| [Kaggle]Super Image Resolution_고화질 이미지 만들기 (0) | 2022.02.07 |
|---|---|
| [Kaggle] CNN Architectures (0) | 2022.02.04 |
| [Kaggle] HeartAttack 예측 (0) | 2022.01.31 |
| [Kaggle] Chest X-Ray 폐암 이미지 분류하기 (0) | 2022.01.29 |
| [Kaggle]Breast Cancer Wisconsin (Diagnostic) Data Set_유방암 분류 (0) | 2022.01.28 |



