
😎 공부하는 징징알파카는 처음이지?
[Kaggle] Web traffic time series forecast 본문
728x90
반응형
220916 작성
<본 블로그는kaggle의 ymalai87416 님의 code와 notebook 을 참고해서 공부하며 작성하였습니다 :-) >
https://www.kaggle.com/code/ymlai87416/web-traffic-time-series-forecast-with-4-model
Web traffic time series forecast with 4 model
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
😎 웹 트래픽 시계열 예측
약 145,000개의 Wikipedia 기사에 대한 미래 웹 트래픽 예측 문제에 대해 참가자가 설계한 최첨단 방법을 테스트
😎 데이터 세트
- 약 145,000개의 시계열로 구성
- 2015년 7월 1일부터 2016년 12월 31일까지 다양한 Wikipedia 기사의 일일 조회수
- train_*.csv
- 교통 데이터를 포함
- 각 행이 특정 기사에 해당하고 각 열이 특정 날짜에 해당하는 csv 파일
- 일부 항목에 데이터가 누락
- 파일 이름에 Wikipedia 프로젝트, 액세스 유형 에이전트 유형 포함
- key_*.csv
- 페이지 이름과 예측에 사용되는 단축 ID 열 간의 매핑을 제공
- sample_submission_*.csv
- 올바른 형식을 보여주는 제출 파일
- train_*.csv
😎 코드 구현
1️⃣ 필요한 라이브러리 & 패키치 로드
- Prophet
- 비선형 추세가 연도별, 주별, 일별 계절성과 휴일 효과에 맞는 가법 모델을 기반으로 시계열 데이터를 예측
!pip install fbprophet
!conda install -c conda-forge fbprophet -y
- error 가 뜨면 plotly 설치!
- fbprophet importing plotly failed. interactive plots will not work.
!pip install plotly- 라이브러리 로드
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from fbprophet import Prophet
import matplotlib.pyplot as plt
import math as math
%matplotlib inline
2️⃣ 데이터 로드
# Load the data
train = pd.read_csv("web-traffic-time-series-forecasting/train_1.csv/train_1.csv")
keys = pd.read_csv("web-traffic-time-series-forecasting/key_1.csv/key_1.csv")
ss = pd.read_csv("web-traffic-time-series-forecasting/sample_submission_1.csv/sample_submission_1.csv")train.head()
3️⃣ 전처리 (누적된 값)
- null 값 찾기!! 굉장히 많다
# Check the data
print("Check the number of records")
print("Number of records: ", train.shape[0], "\n")
print("Null analysis")
empty_sample = train[train.isnull().any(axis=1)]
print("Number of records contain 1+ null: ", empty_sample.shape[0], "\n")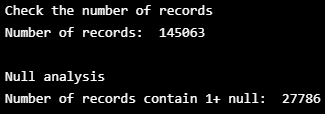
empty_sample.iloc[np.r_[0:10, len(empty_sample)-10:len(empty_sample)]]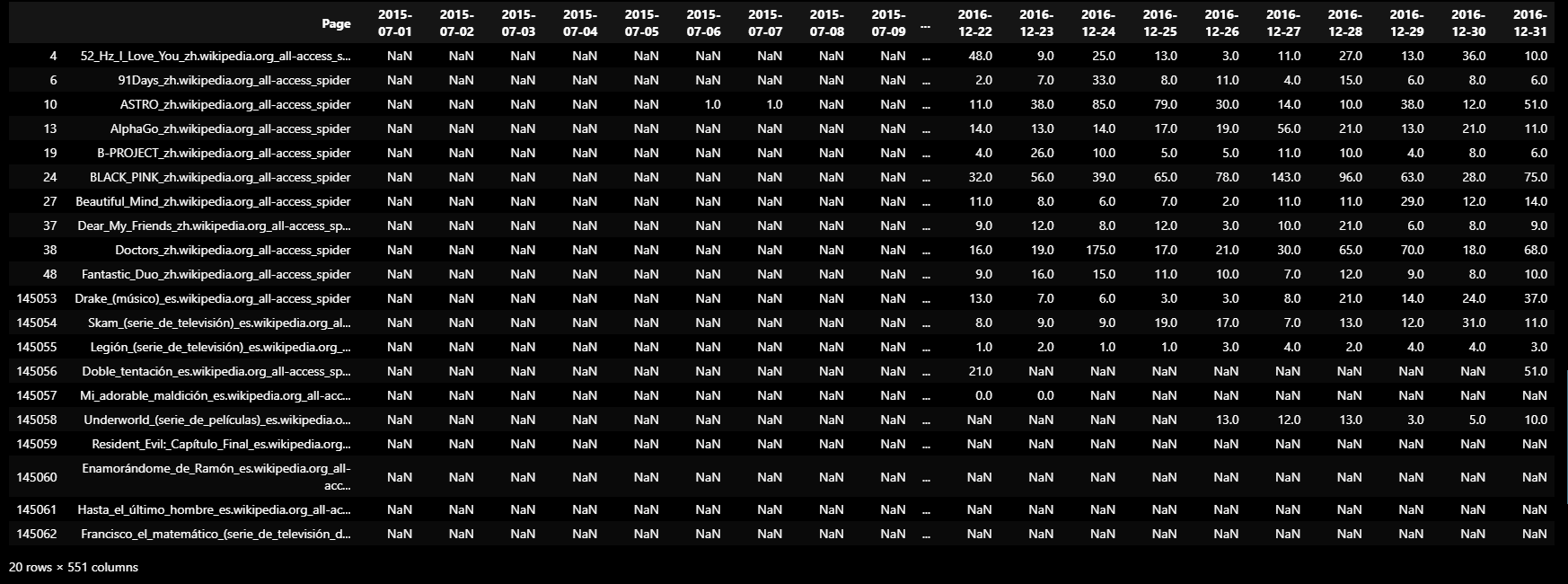
4️⃣ 데이터 시각화
# plot 3 the time series
def plot_time_series(df, row_num, start_col =1, ax=None):
if ax is None:
fig = plt.figure(facecolor='w', figsize=(10, 6))
ax = fig.add_subplot(111)
else:
fig = ax.get_figure()
series_title = df.iloc[row_num, 0]
sample_series = df.iloc[row_num, start_col:]
sample_series.plot(style=".", ax=ax)
ax.set_title("Series: %s" % series_title)
fig, axs = plt.subplots(4,1,figsize=(12,12))
plot_time_series(empty_sample, 1, ax=axs[0])
plot_time_series(empty_sample, 10, ax=axs[1])
plot_time_series(empty_sample, 100, ax=axs[2])
plot_time_series(empty_sample, 1005, ax=axs[3])
plt.tight_layout()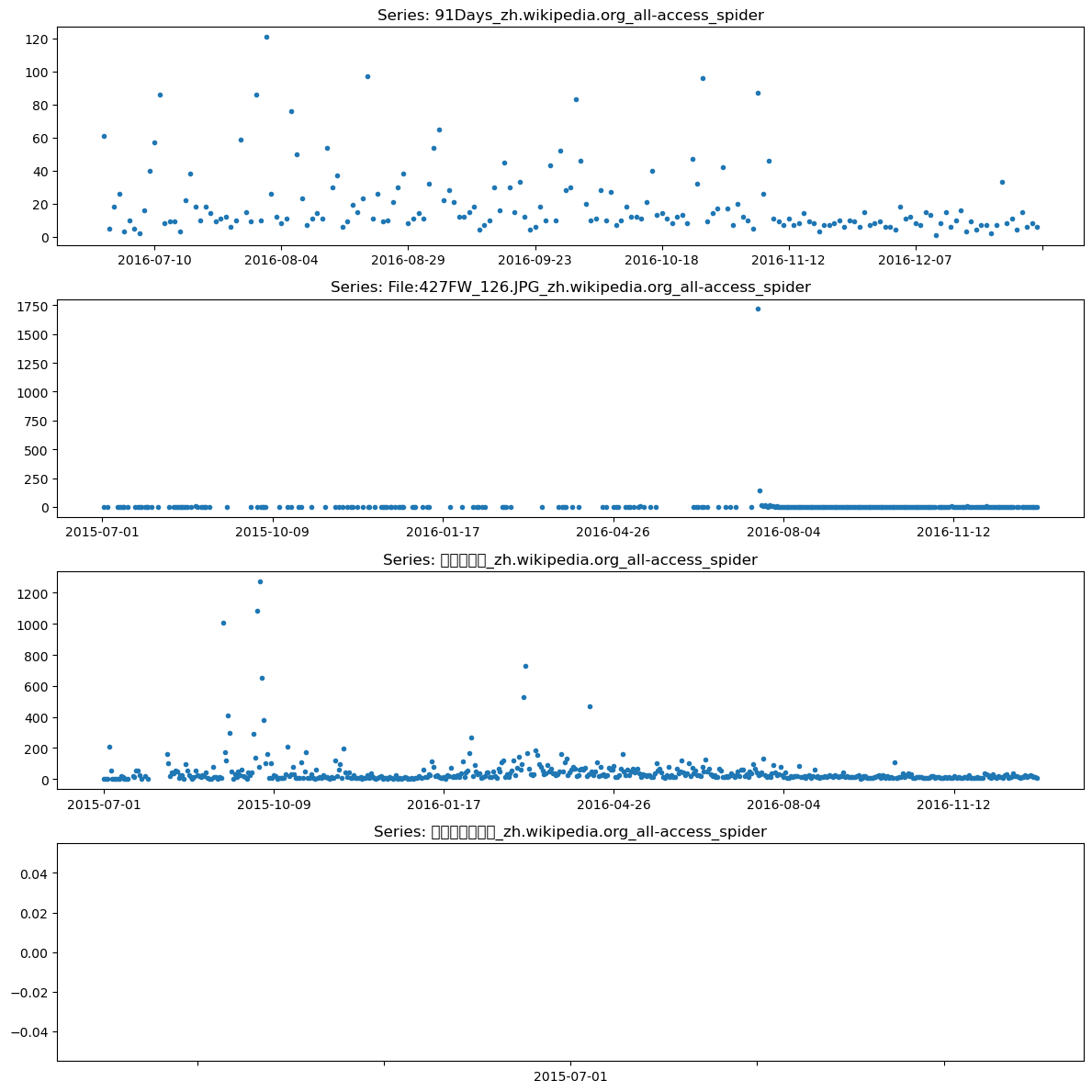
5️⃣ 데이터 변형
- import re
- 정규표현식은 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식
import re
def breakdown_topic(str):
m = re.search('(.*)\_(.*).wikipedia.org\_(.*)\_(.*)', str)
if m is not None:
return m.group(1), m.group(2), m.group(3), m.group(4)
else:
return "", "", "", ""
print(breakdown_topic("Рудова,_Наталья_Александровна_ru.wikipedia.org_all-access_spider"))
print(breakdown_topic("台灣災難列表_zh.wikipedia.org_all-access_spider"))
print(breakdown_topic("File:Memphis_Blues_Tour_2010.jpg_commons.wikimedia.org_mobile-web_all-agents"))
page_details = train.Page.str.extract(r'(?P<topic>.*)\_(?P<lang>.*).wikipedia.org\_(?P<access>.*)\_(?P<type>.*)')
page_details[0:10]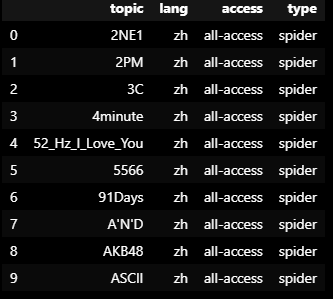
unique_topic = page_details["topic"].unique()
print(unique_topic)
print("Number of distinct topics: ", unique_topic.shape[0])
fig, axs = plt.subplots(3,1,figsize=(12,12))
page_details["lang"].value_counts().sort_index().plot.bar(ax=axs[0])
axs[0].set_title('Language - distribution')
page_details["access"].value_counts().sort_index().plot.bar(ax=axs[1])
axs[1].set_title('Access - distribution')
page_details["type"].value_counts().sort_index().plot.bar(ax=axs[2])
axs[2].set_title('Type - distribution')
plt.tight_layout()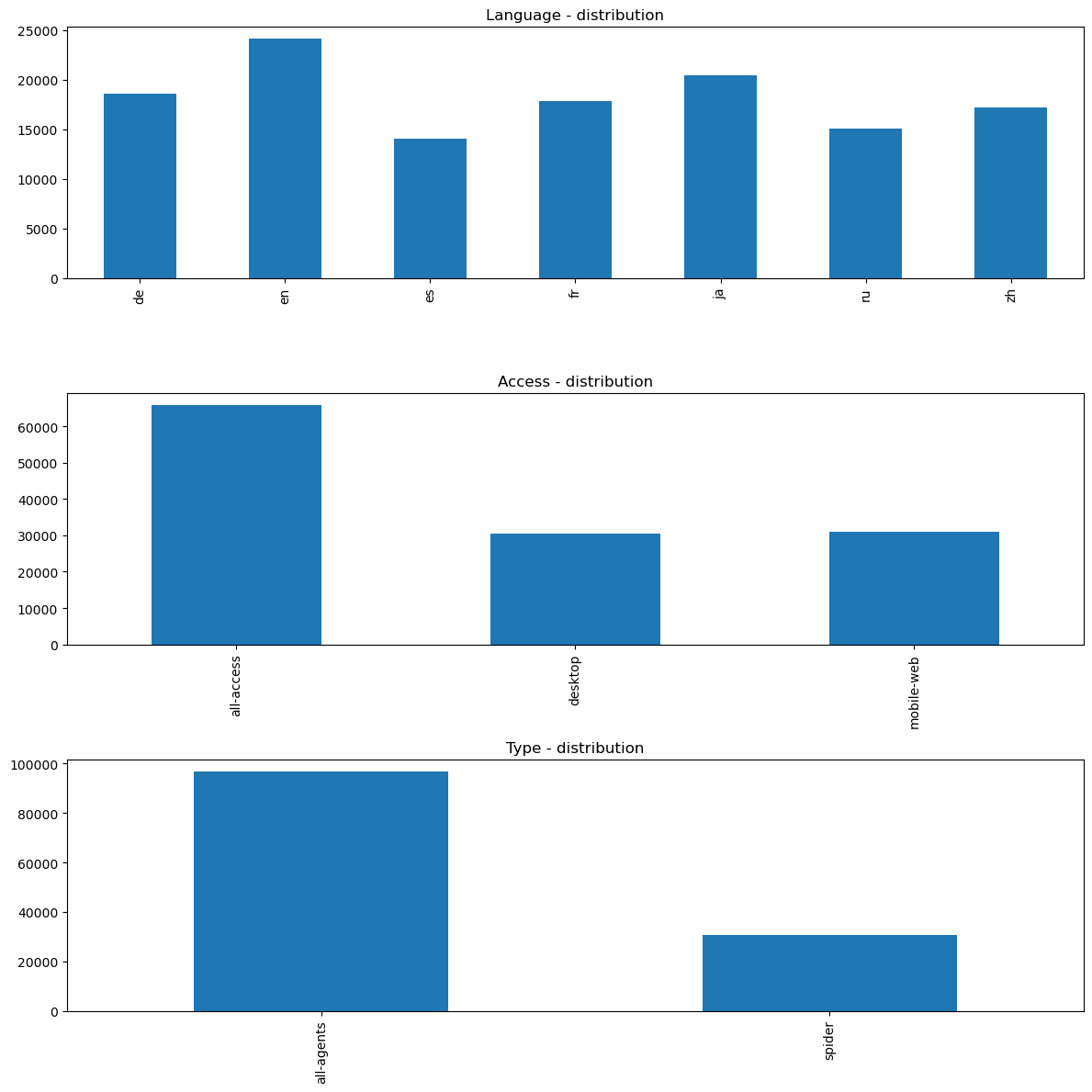
- Split into train and validation dataset
# Generate train and validate dataset
train_df = pd.concat([page_details, train], axis=1)
def get_train_validate_set(train_df, test_percent):
train_end = math.floor((train_df.shape[1]-5) * (1-test_percent))
train_ds = train_df.iloc[:, np.r_[0,1,2,3,4,5:train_end]]
test_ds = train_df.iloc[:, np.r_[0,1,2,3,4,train_end:train_df.shape[1]]]
return train_ds, test_ds
X_train, y_train = get_train_validate_set(train_df, 0.1)
print("The training set sample:")
print(X_train[0:10])
print("The validation set sample:")
print(y_train[0:10])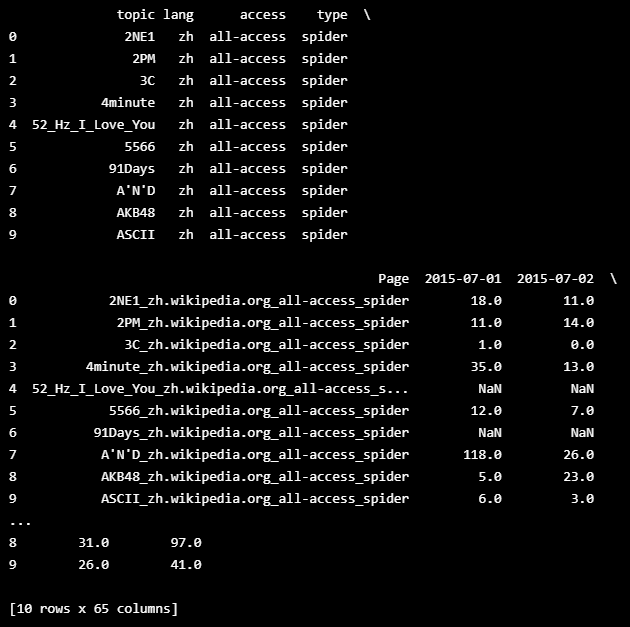
6️⃣ 예측 방법
- 대칭 평균 절대 백분율 오류(SMAPE 또는 sMAPE)
- 백분율(또는 상대) 오류를 기반으로 하는 정확도 측정
- 실제값과 예측값의 평균으로 나누어 구함
- 값이 작을수록 모델의 성능이 좋다
- 0~200% 사이의 확률 값 가져서 결과 해석 용이함
- 데이터 값의 크기가 아닌 비율과 관련된 값이기 대문에 다양한 모델, 성능 비교에 용이
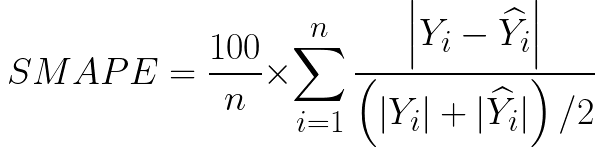
def extract_series(df, row_num, start_idx):
y = df.iloc[row_num, start_idx:]
df = pd.DataFrame({ 'ds': y.index, 'y': y.values})
return dfdef smape(predict, actual, debug=False):
actual = actual.fillna(0)
data = pd.concat([predict, actual], axis=1, keys=['predict', 'actual'])
data = data[data.actual.notnull()]
if debug:
print('debug', data)
evals = abs(data.predict - data.actual) * 1.0 / (abs(data.predict) + abs(data.actual)) * 2
evals[evals.isnull()] = 0
print(np.sum(evals), len(data), np.sum(evals) * 1.0 / len(data))
result = np.sum(evals) / len(data)
return result
# create testing series
testing_series_1 = X_train.iloc[0, 5:494]
testing_series_2 = X_train.iloc[0, 5:494].shift(-1)
testing_series_3 = X_train.iloc[1, 5:494]
testing_series_4 = pd.Series([0,0,0,0])random_series_1 = pd.Series(np.repeat(3, 500))
random_series_2 = pd.Series(np.random.normal(3, 1, 500))
random_series_3 = pd.Series(np.random.normal(500, 20, 500))
random_series_4 = pd.Series(np.repeat(500, 500))# testing 1 same series
print("\nSMAPE score to predict a constant array of 3")
print("Score (same series): %.3f" % smape(random_series_1, random_series_1))
print("Score (same series - 1) %.3f" % smape(random_series_1, random_series_1-1))
print("Score (same series + 1) %.3f" % smape(random_series_1, random_series_1+1))
# testing 2 same series shift by one
print("\nSMAPE score to predict a array of normal distribution around 3")
print("Score (random vs mean) %.3f" % smape(random_series_2, random_series_1))
print("Score (random vs mean-1) %.3f" % smape(random_series_2, random_series_2-1))
print("Score (random vs mean+1) %.3f" % smape(random_series_2, random_series_2+1))
print("Score (random vs mean*0.9) %.3f" % smape(random_series_2, random_series_2*0.9))
print("Score (random vs mean*1.1) %.3f" % smape(random_series_2, random_series_2*1.1))
# testing 3 totally different series
print("\nSMAPE score to predict a array of normal distribution around 500")
print("Score (random vs mean) %.3f" % smape(random_series_3, random_series_4))
print("Score (random vs mean-20) %.3f" % smape(random_series_3, random_series_3-20))
print("Score (random vs mean+20) %.3f" % smape(random_series_3, random_series_3+20))
print("Score (random vs mean*0.9) %.3f" % smape(random_series_3, random_series_3*0.9))
print("Score (random vs mean*1.1) %.3f" % smape(random_series_3, random_series_3*1.1))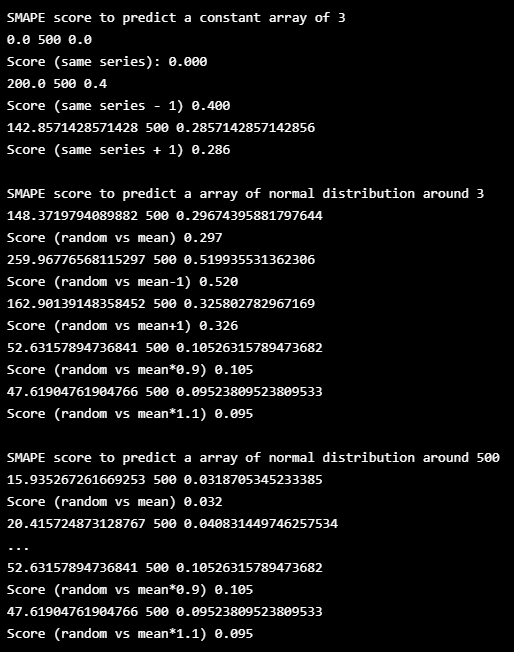
y_true_1 = pd.Series(np.random.normal(1, 1, 500))
y_true_2 = pd.Series(np.random.normal(2, 1, 500))
y_true_3 = pd.Series(np.random.normal(3, 1, 500))
y_pred = pd.Series(np.ones(500))x = np.linspace(0,10,1000)
res_1 = list([smape(y_true_1, i * y_pred) for i in x])
res_2 = list([smape(y_true_2, i * y_pred) for i in x])
res_3 = list([smape(y_true_3, i * y_pred) for i in x])
plt.plot(x, res_1, color='b')
plt.plot(x, res_2, color='r')
plt.plot(x, res_3, color='g')
plt.axvline(x=1, color='k')
plt.axvline(x=2, color='k')
plt.axvline(x=3, color='k')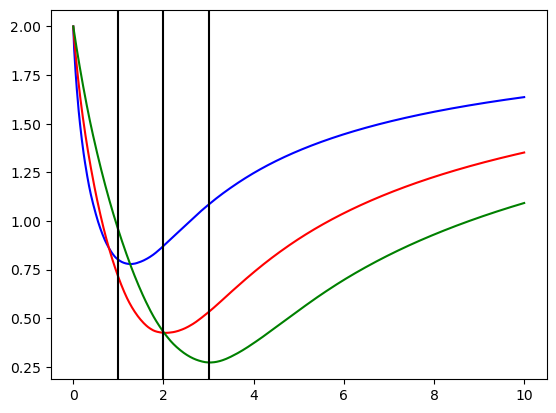
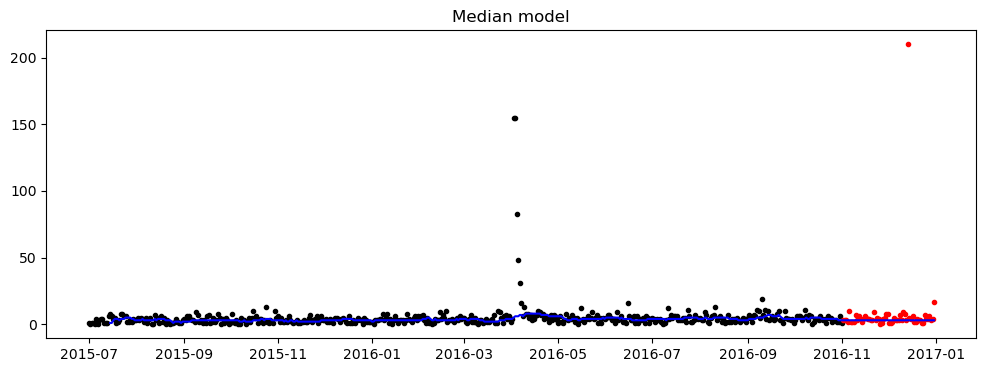
- 간단한 중앙값 모델
def plot_prediction_and_actual_2(train, forecast, actual, xlim=None, ylim=None, figSize=None, title=None):
fig, ax = plt.subplots(1,1,figsize=figSize)
ax.plot(pd.to_datetime(train.index), train.values, 'k.')
ax.plot(pd.to_datetime(actual.index), actual.values, 'r.')
ax.plot(pd.to_datetime(forecast.index), forecast.values, 'b-')
ax.set_title(title)
plt.show()def median_model(df_train, df_actual, p, review=False, figSize=(12, 4)):
def nanmedian_zero(a):
return np.nan_to_num(np.nanmedian(a))
# df_train['y'] = df_train['y'].convert_objects(convert_numeric=True)
df_train['y'] = pd.to_numeric(df_train['y'])
# df_actual['y'] = df_actual['y'].convert_objects(convert_numeric=True)
df_actual['y'] = pd.to_numeric(df_actual['y'])
visits = nanmedian_zero(df_train['y'].values[-p:])
train_series = df_train['y']
train_series.index = df_train.ds
idx = np.arange( p) + np.arange(len(df_train)- p+1)[:,None]
b = [row[row>=0] for row in df_train.y.values[idx]]
pre_forecast = pd.Series(np.append(([float('nan')] * (p-1)), list(map(nanmedian_zero,b))))
pre_forecast.index = df_train.ds
forecast_series = pd.Series(np.repeat(visits, len(df_actual)))
forecast_series.index = df_actual.ds
forecast_series = pre_forecast.append(forecast_series)
actual_series = df_actual.y
actual_series.index = df_actual.ds
if(review):
plot_prediction_and_actual_2(train_series, forecast_series, actual_series, figSize=figSize, title='Median model')
return smape(forecast_series, actual_series)print(train.iloc[[2]])
df_train = extract_series(X_train, 2, 5)
df_actual = extract_series(y_train, 2, 5)
lang = X_train.iloc[2, 1]
score = median_model(df_train.copy(), df_actual.copy(), 15, review=True)
print("The SMAPE score is : %.5f" % score)

- 중앙값 모델 (휴일, 주말, 평일)
- 이렇게.. 노가다의 코드를?
더보기
holiday_en_us = ['2015-01-01', '2015-01-19', '2015-05-25', '2015-07-03', '2015-09-07', '2015-11-26', '2015-11-27', '2015-12-25', '2016-01-01', '2016-01-18', '2016-05-30', '2016-07-04', '2016-09-05', '2016-11-11', '2016-11-24', '2016-12-26', '2017-01-01', '2017-01-02', '2017-01-16', '2017-05-29', '2017-07-04', '2017-09-04', '2017-11-10', '2017-11-23', '2017-12-25']
holiday_en_uk = ['2015-01-01', '2015-04-03', '2015-05-04', '2015-05-25', '2015-12-25', '2015-12-26', '2015-12-28', '2016-01-01', '2016-03-25', '2016-05-02', '2016-05-30', '2016-12-26', '2016-12-27', '2017-01-01', '2017-04-14', '2017-05-01', '2017-05-29', '2017-12-25', '2017-12-26']
holiday_en_canada = ['2015-01-01', '2015-07-01', '2015-09-07', '2015-12-25', '2016-01-01', '2016-07-01', '2016-09-05', '2016-12-25', '2017-01-01', '2017-07-01', '2017-07-03', '2017-09-04', '2017-12-25']
holiday_ru_russia = ['2015-01-01', '2015-01-02', '2015-01-05', '2015-01-06', '2015-01-07', '2015-01-08', '2015-01-09', '2015-02-23', '2015-03-09', '2015-05-01', '2015-05-04', '2015-05-09', '2015-05-11', '2015-06-12', '2015-11-04', '2016-01-01', '2016-01-04', '2016-01-05', '2016-01-06', '2016-01-07', '2016-02-22', '2016-02-23', '2016-03-08', '2016-05-01', '2016-05-09', '2016-06-12', '2016-06-13', '2016-11-04', '2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04', '2017-01-05', '2017-01-06', '2017-01-07', '2017-02-23', '2017-02-24', '2017-03-08', '2017-05-01', '2017-05-08', '2017-05-09', '2017-06-12', '2017-11-04', '2017-11-06']
holiday_es_mexico = ['2015-01-01', '2015-02-02', '2015-03-16', '2015-04-02', '2015-04-03', '2015-05-01', '2015-09-16', '2015-10-12', '2015-11-02', '2015-11-16', '2015-12-12', '2015-12-25', '2016-01-01', '2016-02-01', '2016-03-21', '2016-03-24', '2016-03-25', '2016-05-01', '2016-09-16', '2016-10-12', '2016-11-02', '2016-11-21', '2016-12-12', '2016-12-25', '2016-12-26', '2017-01-01', '2017-01-02', '2017-02-06', '2017-03-20', '2017-04-13', '2017-04-14', '2017-05-01', '2017-09-16', '2017-10-12', '2017-11-02', '2017-11-20', '2017-12-12', '2017-12-25']
holiday_es_spain = ['2017-01-01', '2017-01-06', '2017-04-14', '2017-05-01', '2017-08-15', '2017-10-12', '2017-11-01', '2017-12-06', '2017-12-08', '2017-12-25', '2016-01-01', '2016-01-06', '2016-03-25', '2016-05-01', '2016-08-15', '2016-10-12', '2016-11-01', '2016-12-06', '2016-12-08', '2016-12-25', '2015-01-01', '2015-01-06', '2015-04-03', '2015-05-01', '2015-10-12', '2015-11-01', '2015-12-06', '2015-12-08', '2015-12-25']
holiday_es_colombia = ['2015-01-01', '2015-01-12', '2015-03-23', '2015-04-02', '2015-04-03', '2015-05-01', '2015-05-18', '2015-06-08', '2015-06-15', '2015-06-29', '2015-07-20', '2015-08-07', '2015-08-17', '2015-10-12', '2015-11-02', '2015-11-16', '2015-12-08', '2015-12-25', '2016-01-01', '2016-01-11', '2016-03-21', '2016-03-24', '2016-03-25', '2016-05-01', '2016-05-09', '2016-05-30', '2016-06-06', '2016-07-04', '2016-07-20', '2016-08-07', '2016-08-15', '2016-10-17', '2016-11-07', '2016-11-14', '2016-12-08', '2016-12-25', '2017-01-01', '2017-01-09', '2017-03-20', '2017-04-13', '2017-04-14', '2017-05-01', '2017-05-29', '2017-06-19', '2017-06-26', '2017-07-03', '2017-07-20', '2017-08-07', '2017-08-15', '2017-10-16', '2017-11-06', '2017-11-13', '2017-12-08', '2017-12-25']
holiday_fr_france = ['2015-01-01', '2015-04-06', '2015-05-01', '2015-05-08', '2015-05-14', '2015-05-25', '2015-07-14', '2015-08-15', '2015-11-01', '2015-11-11', '2015-12-25', '2016-01-01', '2016-03-28', '2016-05-01', '2016-05-05', '2016-05-08', '2016-05-16', '2016-07-14', '2016-08-15', '2016-11-01', '2016-11-11', '2016-12-25', '2017-01-01', '2017-04-17', '2017-05-01', '2017-05-08', '2017-05-25', '2017-06-05', '2017-07-14', '2017-08-15', '2017-11-01', '2017-11-11', '2017-12-25']
holiday_jp_japan = ['2015-01-01', '2015-01-12', '2015-02-11', '2015-03-21', '2015-04-29', '2015-05-03', '2015-05-04', '2015-05-05', '2015-05-06', '2015-07-20', '2015-09-21', '2015-09-22', '2015-09-23', '2015-10-12', '2015-11-03', '2015-11-23', '2015-12-23', '2016-01-01', '2016-01-11', '2016-02-11', '2016-03-21', '2016-04-29', '2016-05-03', '2016-05-04', '2016-05-05', '2016-07-18', '2016-08-11', '2016-09-19', '2016-09-22', '2016-10-10', '2016-11-03', '2016-11-23', '2016-12-23', '2017-01-01', '2017-01-09', '2017-02-11', '2017-03-20', '2017-04-29', '2017-05-03', '2017-05-04', '2017-05-05', '2017-07-17', '2017-08-11', '2017-09-18', '2017-09-22', '2017-10-09', '2017-11-03', '2017-11-23', '2017-12-23']
holiday_de_germany = ['2015-01-01', '2015-04-03', '2015-04-06', '2015-05-01', '2015-05-14', '2015-05-14', '2015-05-25', '2015-10-03', '2015-12-25', '2015-12-26', '2016-01-01', '2016-03-25', '2016-03-28', '2016-05-01', '2016-05-05', '2016-05-16', '2016-10-03', '2016-12-25', '2016-12-26', '2017-01-01', '2017-04-14', '2017-04-17', '2017-05-01', '2017-05-25', '2017-06-05', '2017-10-03', '2017-10-31', '2017-12-25', '2017-12-26']
holiday_de_austria = ['2015-01-01', '2015-01-06', '2015-04-06', '2015-05-01', '2015-05-14', '2015-05-25', '2015-06-04', '2015-08-15', '2015-10-26', '2015-11-01', '2015-12-08', '2015-12-25', '2015-12-26', '2016-01-01', '2016-01-06', '2016-03-28', '2016-05-01', '2016-05-05', '2016-05-16', '2016-05-26', '2016-08-15', '2016-10-26', '2016-11-01', '2016-12-08', '2016-12-25', '2016-12-26', '2017-01-01', '2017-01-06', '2017-04-17', '2017-05-01', '2017-05-25', '2017-06-05', '2017-06-15', '2017-08-15', '2017-10-26', '2017-11-01', '2017-12-08', '2017-12-25', '2017-12-26']
holiday_de_switzerland = ['2015-01-01', '2015-04-03', '2015-05-14', '2015-08-01', '2015-12-25', '2016-01-01', '2016-03-25', '2016-05-05', '2016-08-01', '2016-12-25', '2017-01-01', '2017-04-14', '2017-05-25', '2017-08-01', '2017-12-25']
holiday_zh_hongkong = ['2015-01-01', '2015-02-19', '2015-02-20', '2015-04-03', '2015-04-04', '2015-04-05', '2015-04-06', '2015-04-07', '2015-05-01', '2015-05-25', '2015-06-20', '2015-07-01', '2015-09-03', '2015-09-28', '2015-10-01', '2015-10-21', '2015-12-25', '2015-12-26', '2016-01-01', '2016-02-08', '2016-02-09', '2016-02-10', '2016-03-25', '2016-03-26', '2016-03-28', '2016-04-04', '2016-05-01', '2016-05-02', '2016-05-14', '2016-06-09', '2016-07-01', '2016-09-16', '2016-10-01', '2016-10-10', '2016-12-25', '2016-12-26', '2016-12-27', '2017-01-01', '2017-01-02', '2017-01-28', '2017-01-30', '2017-01-31', '2017-04-04', '2017-04-14', '2017-04-15', '2017-04-17', '2017-05-01', '2017-05-03', '2017-05-30', '2017-07-01', '2017-10-01', '2017-10-02', '2017-10-05', '2017-10-28', '2017-12-25', '2017-12-26']
holiday_zh_taiwan = ['2015-01-01', '2015-02-18', '2015-02-19', '2015-02-20', '2015-02-21', '2015-02-22', '2015-02-23', '2015-02-23', '2015-02-27', '2015-04-03', '2015-04-05', '2015-04-06', '2015-06-19', '2015-06-20', '2015-09-28', '2015-10-09', '2015-10-10', '2016-01-01', '2016-02-07', '2016-02-08', '2016-02-09', '2016-02-10', '2016-02-11', '2016-02-12', '2016-02-29', '2016-04-04', '2016-04-05', '2016-06-09', '2016-06-10', '2016-09-15', '2016-09-16', '2016-09-28', '2016-10-10', '2017-01-01', '2017-01-02', '2017-01-27', '2017-01-28', '2017-01-29', '2017-01-30', '2017-01-31', '2017-02-01', '2017-02-27', '2017-02-28', '2017-04-03', '2017-04-04', '2017-05-01', '2017-05-29', '2017-05-30', '2017-10-04', '2017-10-09', '2017-10-10']
holidays_en_us = pd.DataFrame({
'holiday': 'US public holiday',
'ds': pd.to_datetime(holiday_en_us),
'lower_window': 0,
'upper_window': 0,
})
holidays_en_uk = pd.DataFrame({
'holiday': 'UK public holiday',
'ds': pd.to_datetime(holiday_en_uk),
'lower_window': 0,
'upper_window': 0,
})
holidays_en_canada = pd.DataFrame({
'holiday': 'Canada public holiday',
'ds': pd.to_datetime(holiday_en_canada),
'lower_window': 0,
'upper_window': 0,
})
holidays_en = pd.concat((holidays_en_us, holidays_en_uk, holidays_en_canada))
holidays_ru_russia = pd.DataFrame({
'holiday': 'Russia public holiday',
'ds': pd.to_datetime(holiday_ru_russia),
'lower_window': 0,
'upper_window': 0,
})
holidays_ru = holidays_ru_russia
holidays_es_mexico = pd.DataFrame({
'holiday': 'Mexico public holiday',
'ds': pd.to_datetime(holiday_es_mexico),
'lower_window': 0,
'upper_window': 0,
})
holidays_es_spain = pd.DataFrame({
'holiday': 'Spain public holiday',
'ds': pd.to_datetime(holiday_es_spain),
'lower_window': 0,
'upper_window': 0,
})
holidays_es_colombia = pd.DataFrame({
'holiday': 'Colombia public holiday',
'ds': pd.to_datetime(holiday_es_colombia),
'lower_window': 0,
'upper_window': 0,
})
holidays_es = pd.concat((holidays_es_mexico, holidays_es_spain, holidays_es_colombia))
holidays_fr_france = pd.DataFrame({
'holiday': 'France public holiday',
'ds': pd.to_datetime(holiday_fr_france),
'lower_window': 0,
'upper_window': 0,
})
holidays_fr = holidays_fr_france
holidays_jp_japan = pd.DataFrame({
'holiday': 'Japan public holiday',
'ds': pd.to_datetime(holiday_jp_japan),
'lower_window': 0,
'upper_window': 0,
})
holidays_jp = holidays_jp_japan
holidays_de_germany = pd.DataFrame({
'holiday': 'Germany public holiday',
'ds': pd.to_datetime(holiday_de_germany),
'lower_window': 0,
'upper_window': 0,
})
holidays_de_austria = pd.DataFrame({
'holiday': 'Austria public holiday',
'ds': pd.to_datetime(holiday_de_austria),
'lower_window': 0,
'upper_window': 0,
})
holidays_de_switzerland = pd.DataFrame({
'holiday': 'Switzerland public holiday',
'ds': pd.to_datetime(holiday_de_switzerland),
'lower_window': 0,
'upper_window': 0,
})
holidays_de = pd.concat((holidays_de_germany, holidays_de_austria, holidays_de_switzerland))
holidays_zh_hongkong = pd.DataFrame({
'holiday': 'HK public holiday',
'ds': pd.to_datetime(holiday_zh_hongkong),
'lower_window': 0,
'upper_window': 0,
})
holidays_zh_taiwan = pd.DataFrame({
'holiday': 'Taiwan public holiday',
'ds': pd.to_datetime(holiday_zh_taiwan),
'lower_window': 0,
'upper_window': 0,
})
holidays_zh = pd.concat((holidays_zh_hongkong, holidays_zh_taiwan))
holidays_dict = {"en": holidays_en,
"ru": holidays_ru,
"es": holidays_es,
"fr": holidays_fr,
"ja": holidays_jp,
"de": holidays_de,
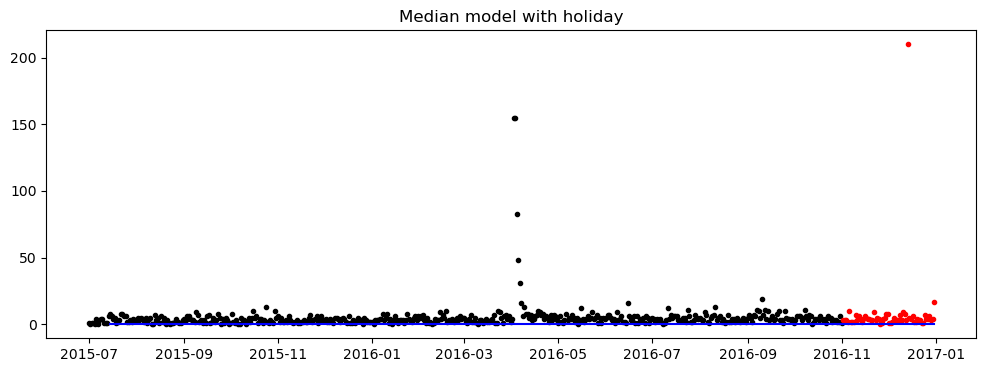
"zh": holidays_zh}def median_holiday_model(df_train, df_actual, p, lang, review=False, figSize=(12, 4)):
# Split the train and actual set
df_train['ds'] = pd.to_datetime(df_train['ds'])
df_actual['ds'] = pd.to_datetime(df_actual['ds'])
train_series = df_train['y']
train_series.index = df_train.ds
if(isinstance(lang, float) and math.isnan(lang)):
df_train['holiday'] = df_train.ds.dt.dayofweek >=5
df_actual['holiday'] = df_actual.ds.dt.dayofweek >=5
else:
df_train['holiday'] = (df_train.ds.dt.dayofweek >=5) | df_train.ds.isin(holidays_dict[lang].ds)
df_actual['holiday'] = (df_actual.ds.dt.dayofweek >=5) | df_actual.ds.isin(holidays_dict[lang].ds)
# Combine the train and actual set
predict_holiday = median_holiday_helper(df_train, df_actual[df_actual.holiday], p, True)
predict_non_holiday = median_holiday_helper(df_train, df_actual[~df_actual.holiday], p, False)
forecast_series = predict_non_holiday.combine_first(predict_holiday)
actual_series = df_actual.y
actual_series.index = df_actual.ds
if(review):
plot_prediction_and_actual_2(train_series, forecast_series, actual_series, figSize=figSize, title='Median model with holiday')
return smape(forecast_series, actual_series)
def median_holiday_helper(df_train, df_actual, p, holiday):
def nanmedian_zero(a):
return np.nan_to_num(np.nanmedian(a))
df_train['y'] = pd.to_numeric(df_train['y'])
df_actual['y'] = pd.to_numeric(df_actual['y'])
sample = df_train[-p:]
if(holiday):
sample = sample[sample['holiday']]
else:
sample = sample[~sample['holiday']]
visits = nanmedian_zero(sample['y'])
idx = np.arange( p) + np.arange(len(df_train)- p+1)[:,None]
b = [row[row>=0] for row in df_train.y.values[idx]]
pre_forecast = pd.Series(np.append(([float('nan')] * (p-1)), list(map(nanmedian_zero,b))))
pre_forecast.index = df_train.ds
forecast_series = pd.Series(np.repeat(visits, len(df_actual)))
forecast_series.index = df_actual.ds
forecast_series = pre_forecast.append(forecast_series)
return forecast_seriesprint(train.iloc[[2]])
df_train = extract_series(X_train, 2, 5)
df_actual = extract_series(y_train, 2, 5)
lang = X_train.iloc[2, 1]
score = median_holiday_model(df_train.copy(), df_actual.copy(), 15, lang, review=True)
print("The SMAPE score is : %.5f" % score)
- ARIMA 모델
# This is to demo the ARIMA model
print(train.iloc[[2]])
df_train = extract_series(X_train, 2, 5)
df_actual = extract_series(y_train, 2, 5)
lang = X_train.iloc[2, 1]
- ARMIA 함수 였는데, 에러 나서 그냥 코드침... 원인은 모름
from statsmodels.tsa.arima.model import ARIMA
import warnings
df_train = df_train.fillna(0)
train_series = df_train.y
train_series.index = df_train.ds
result = None
#arima = ARIMA(train_series , order=(2,1,2))
arima = ARIMA(train_series, order=(1,0,0))
result = arima.fit()
start_idx = df_train.ds[1]
end_idx = df_actual.ds.max()
forecast_series = result.predict(start_idx, end_idx,typ='levels')
actual_series = df_actual.y
actual_series.index = pd.to_datetime(df_actual.ds)
actual_series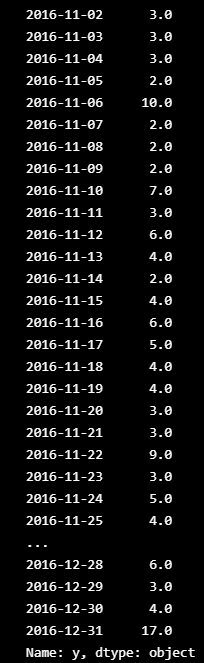
plot_prediction_and_actual_2(train_series, forecast_series, actual_series, figSize=(12, 4), title='ARIMA model')
score = smape(forecast_series, actual_series)
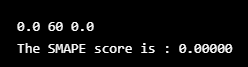
print("The SMAPE score is : %.5f" % score)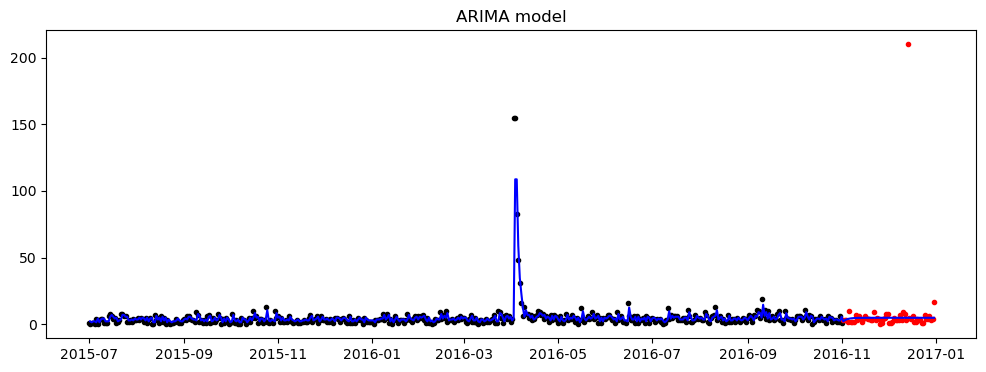

- Facebook prophet library
def plot_prediction_and_actual(model, forecast, actual, xlim=None, ylim=None, figSize=None, title=None):
fig, ax = plt.subplots(1,1,figsize=figSize)
ax.set_ylim(ylim)
ax.plot(pd.to_datetime(actual.ds), actual.y, 'r.')
model.plot(forecast, ax=ax);
ax.set_title(title)
plt.show()# simple linear model
def normal_model(df_train, df_actual, review=False):
start_date = df_actual.ds.min()
end_date = df_actual.ds.max()
actual_series = df_actual.y.copy()
actual_series.index = df_actual.ds
df_train['y'] = df_train['y'].astype('float')
df_actual['y'] = df_actual['y'].astype('float')
m = Prophet()
m.fit(df_train)
future = m.make_future_dataframe(periods=60)
forecast = m.predict(future)
if(review):
ymin = min(df_actual.y.min(), df_train.y.min()) -100
ymax = max(df_actual.y.max(), df_train.y.max()) +100
#
plot_prediction_and_actual(m, forecast, df_actual, ylim=[ymin, ymax], figSize=(12,4), title='Normal model')
mask = (forecast['ds'] >= start_date) & (forecast['ds'] <= end_date)
forecast_series = forecast[mask].yhat
forecast_series.index = forecast[mask].ds
forecast_series[forecast_series < 0] = 0
return smape(forecast_series, actual_series)
def holiday_model(df_train, df_actual, lang, review=False):
start_date = df_actual.ds.min()
end_date = df_actual.ds.max()
actual_series = df_actual.y.copy()
actual_series.index = df_actual.ds
df_train['y'] = df_train['y'].astype('float')
df_actual['y'] = df_actual['y'].astype('float')
if(isinstance(lang, float) and math.isnan(lang)):
holidays = None
else:
holidays = holidays_dict[lang]
m = Prophet(holidays=holidays)
m.fit(df_train)
future = m.make_future_dataframe(periods=60)
forecast = m.predict(future)
if(review):
ymin = min(df_actual.y.min(), df_train.y.min()) -100
ymax = max(df_actual.y.max(), df_train.y.max()) +100
plot_prediction_and_actual(m, forecast, df_actual, ylim=[ymin, ymax], figSize=(12,4), title='Holiday model')
mask = (forecast['ds'] >= start_date) & (forecast['ds'] <= end_date)
forecast_series = forecast[mask].yhat
forecast_series.index = forecast[mask].ds
forecast_series[forecast_series < 0] = 0
return smape(forecast_series, actual_series)
def yearly_model(df_train, df_actual, lang, review=False):
start_date = df_actual.ds.min()
end_date = df_actual.ds.max()
actual_series = df_actual.y.copy()
actual_series.index = df_actual.ds
df_train['y'] = df_train['y'].astype('float')
df_actual['y'] = df_actual['y'].astype('float')
if(isinstance(lang, float) and math.isnan(lang)):
holidays = None
else:
holidays = holidays_dict[lang]
m = Prophet(holidays=holidays, yearly_seasonality=True)
m.fit(df_train)
future = m.make_future_dataframe(periods=60)
forecast = m.predict(future)
if(review):
ymin = min(df_actual.y.min(), df_train.y.min()) -100
ymax = max(df_actual.y.max(), df_train.y.max()) +100
plot_prediction_and_actual(m, forecast, df_actual, ylim=[ymin, ymax], figSize=(12,4), title='Yealry model')
mask = (forecast['ds'] >= start_date) & (forecast['ds'] <= end_date)
forecast_series = forecast[mask].yhat
forecast_series.index = forecast[mask].ds
forecast_series[forecast_series < 0] = 0
return smape(forecast_series, actual_series)# log model
def normal_model_log(df_train, df_actual, review=False):
start_date = df_actual.ds.min()
end_date = df_actual.ds.max()
actual_series = df_actual.y.copy()
actual_series.index = df_actual.ds
df_train['y'] = df_train['y'].astype('float')
df_train.y = np.log1p(df_train.y)
df_actual['y'] = df_actual['y'].astype('float')
df_actual.y = np.log1p(df_actual.y)
m = Prophet()
m.fit(df_train)
future = m.make_future_dataframe(periods=60)
forecast = m.predict(future)
if(review):
ymin = min(df_actual.y.min(), df_train.y.min()) -2
ymax = max(df_actual.y.max(), df_train.y.max()) +2
plot_prediction_and_actual(m, forecast, df_actual, ylim=[ymin, ymax], figSize=(12,4), title='Normal model in log')
mask = (forecast['ds'] >= start_date) & (forecast['ds'] <= end_date)
forecast_series = np.expm1(forecast[mask].yhat)
forecast_series.index = forecast[mask].ds
forecast_series[forecast_series < 0] = 0
return smape(forecast_series, actual_series)
def holiday_model_log(df_train, df_actual, lang, review=False):
start_date = df_actual.ds.min()
end_date = df_actual.ds.max()
actual_series = df_actual.y.copy()
actual_series.index = df_actual.ds
df_train['y'] = df_train['y'].astype('float')
df_train.y = np.log1p(df_train.y)
df_actual['y'] = df_actual['y'].astype('float')
df_actual.y = np.log1p(df_actual.y)
if(isinstance(lang, float) and math.isnan(lang)):
holidays = None
else:
holidays = holidays_dict[lang]
m = Prophet(holidays=holidays)
m.fit(df_train)
future = m.make_future_dataframe(periods=60)
forecast = m.predict(future)
if(review):
ymin = min(df_actual.y.min(), df_train.y.min()) -2
ymax = max(df_actual.y.max(), df_train.y.max()) +2
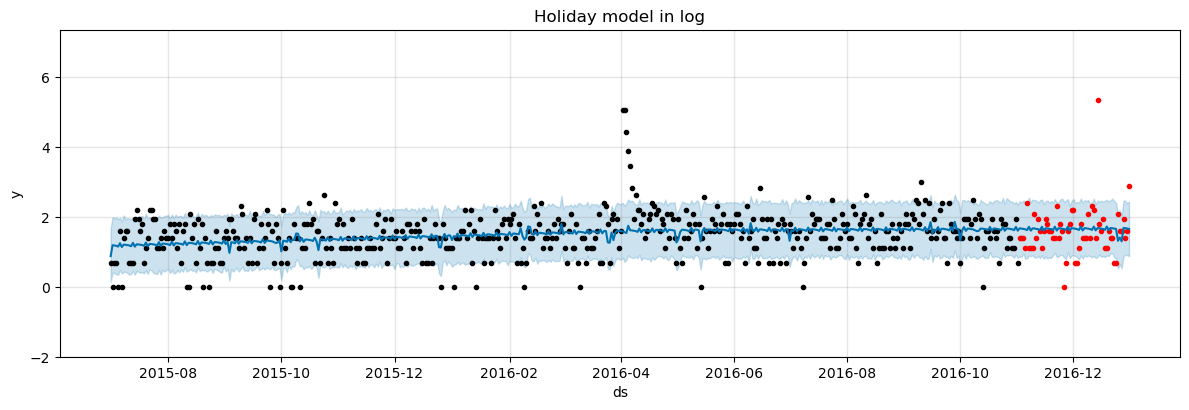
plot_prediction_and_actual(m, forecast, df_actual, ylim=[ymin, ymax], figSize=(12,4), title='Holiday model in log')
mask = (forecast['ds'] >= start_date) & (forecast['ds'] <= end_date)
forecast_series = np.expm1(forecast[mask].yhat)
forecast_series.index = forecast[mask].ds
forecast_series[forecast_series < 0] = 0
return smape(forecast_series, actual_series)
def yearly_model_log(df_train, df_actual, lang, review=False):
start_date = df_actual.ds.min()
end_date = df_actual.ds.max()
actual_series = df_actual.y.copy()
actual_series.index = df_actual.ds
df_train['y'] = df_train['y'].astype('float')
df_train.y = np.log1p(df_train.y)
df_actual['y'] = df_actual['y'].astype('float')
df_actual.y = np.log1p(df_actual.y)
if(isinstance(lang, float) and math.isnan(lang)):
holidays = None
else:
holidays = holidays_dict[lang]
m = Prophet(holidays=holidays, yearly_seasonality=True)
m.fit(df_train)
future = m.make_future_dataframe(periods=60)
forecast = m.predict(future)
if(review):
ymin = min(df_actual.y.min(), df_train.y.min()) -2
ymax = max(df_actual.y.max(), df_train.y.max()) +2
plot_prediction_and_actual(m, forecast, df_actual, ylim=[ymin, ymax], figSize=(12,4), title='Yearly model in log')
mask = (forecast['ds'] >= start_date) & (forecast['ds'] <= end_date)
forecast_series = np.expm1(forecast[mask].yhat)
forecast_series.index = forecast[mask].ds
forecast_series[forecast_series < 0] = 0
return smape(forecast_series, actual_series)# This is to demo the facebook prophet model
print(train.iloc[[2]])
df_train = extract_series(X_train, 2, 5)
df_actual = extract_series(y_train, 2, 5)
lang = X_train.iloc[2, 1]
score = holiday_model_log(df_train.copy(), df_actual.copy(), lang, review=True)
print("The SMAPE score is : %.5f" % score)
728x90
반응형
'👩💻 인공지능 (ML & DL) > Serial Data' 카테고리의 다른 글
| 다양한 유형의 Time series forecasting model (시계열 데이터) (1) | 2022.09.19 |
|---|---|
| [Kaggle] Smart Home Dataset with weather Information (1) | 2022.09.16 |
| [논문리뷰] Comparison between ARIMA and Deep Learning Modelsfor Temperature Forecasting (1) | 2022.09.15 |
| tsod: Anomaly Detection for time series data (0) | 2022.09.15 |
| [DACON] 동서발전 태양광 발전량 예측 AI 경진대회 (0) | 2022.09.14 |
'👩💻 인공지능 (ML & DL)/Serial Data' Related Articles
more




Comments